=PIVOTBY(row_fields, col_fields, values, function, [field_headers], [row_total_depth], [row_sort_order], [col_total_depth], [col_sort_order], [filter_array], [relative_to])- row_fields - The values to use when grouping rows.
- col_fields - The values to use when grouping columns.
- values - The values to aggregate.
- function - The calculation to run when aggregating.
- field_headers - [optional] 0 = No, 1 = Yes, don't show, 2 = No, generate, 3 = Yes, show.
- row_total_depth - [optional] Enable or disable row totals. 0 = None, 1 = Grand Totals, 2 = Grand and Subtotals, -1 = Grand Totals at top, -2 = Both at top.
- row_sort_order - [optional] A column number indicating how rows should be sorted. Negative numbers = descending order.
- col_total_depth - [optional] Enable or disable column totals. 0 = None, 1 = Grand Totals, 2 = Grand and Subtotals, -1 = Grand Totals at top, -2 = Both at top.
- col_sort_order - [optional] A column number indicating how columns should be sorted. Negative numbers = descending order.
- filter_array - [optional] Logic to exclude specific rows.
- relative_to - [optional] Where to find values for the 2nd argument of a function. 0 = column totals (default), 1 = Row Totals, 2 = Grand Totals, 3 = Parent Col Total, 4 = Parent Row Total.
Using the PIVOTBY function
The PIVOTBY function is designed to summarize data by grouping rows and columns. The result is a dynamic summary table created with a single formula. The result from the PIVOTBY function is similar to the output from a Pivot Table, but without formatting. The table returned by the PIVOTBY function is fully dynamic and will immediately recalculate when source data changes. Here is a brief list of PIVOTBY features and limitations:
- A simple and flexible way to make a summary table with a formula.
- Can apply aggregation functions like SUM, AVERAGE, COUNT, COUNTA, etc.
- Does not require a Pivot Table or helper columns.
- Can group by more than one level (i.e., Region and Color, etc.).
- Can group by row and by column.
- Returns a dynamic array that automatically updates when data changes.
- Able to exclude specific rows in the source data with logical expressions.
- Does not apply formatting; you must apply formatting manually.
- Only available in Excel 365.
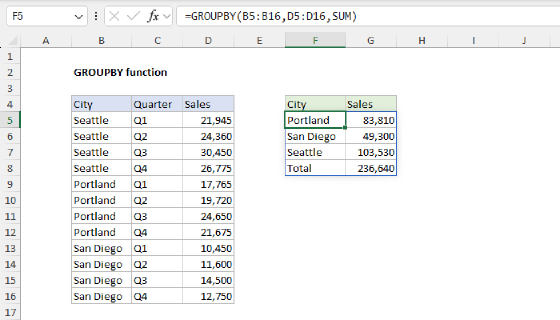
The PIVOTBY function is similar to the GROUPBY function. The difference is that PIVOTBY can group by row and column, whereas GROUPBY can group by row only.
Table of Contents
- PIVOTBY basic example
- PIVOTBY rows vs. columns
- PIVOTBY with field headers
- PIVOTBY calculation options
- PIVOTBY with multiple calculations
- PIVOTBY with custom headers
- PIVOTBY with multiple columns
- PIVOTBY total options
- PIVOTBY sort options
- PIVOTBY with filter array
- PIVOTBY with custom LAMBDA
- PIVOTBY with a dynamic range
Basic Example
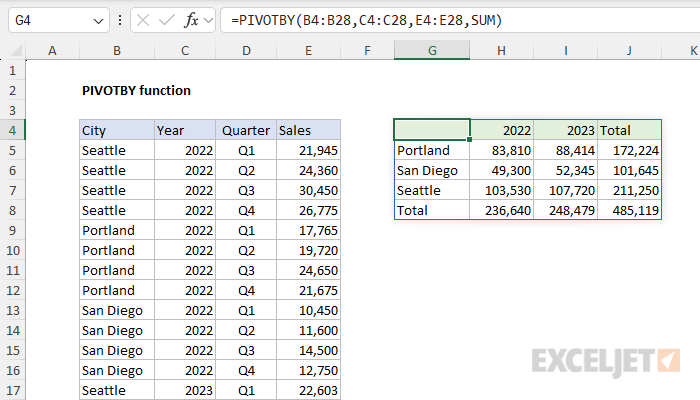
The PIVOTBY function takes 11 arguments, but only the first four are required. In the worksheet below, we use the PIVOTBY function to summarize sales by city and year. The formula in cell F5 is:
=PIVOTBY(B5:B28,C5:C28,E5:E28,SUM)
For this example, PIVOTBY is configured with three arguments as follows:
- row_fields - provided as the range B4:B28, which contains City names.
- col_fields - provided as the range C4:C28 which contains Years.
- values - provided as the range E4:E28, which contains Sales.
- function - provided as SUM, the calculation to perform during aggregation.
With the inputs above, the PIVOTBY function sums sales by city in rows and sales by year in columns. The entire table in G4:J8 is returned in one step. Notice that we have included the header row in row_fields, col_fields, and values, but it is not displayed. PIVOTBY will try to detect a header row automatically so that it won't be included in value calculations. However, PIVOTBY will not display headers in the output unless enabled explicitly by the field_headers argument. Note also that PIVOTBY includes a Total row and Total column by default.
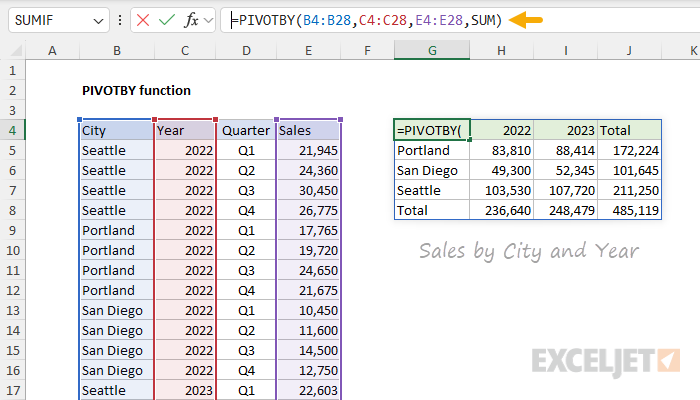
The beauty of Pivot Tables is that you can "pivot" data to show different kinds of summaries. As the name suggests, the PIVOTBY function can also pivot data. For example, in the worksheet below, we have rearranged the inputs to row_fields and col_fields to show Sales by Year and Quarter.
- row_fields - provided as the range D4:D28, which contains Quarters.
- col_fields - provided as the range C4:C28 which contains Years.
- values - provided as the range E4:E28, which contains Sales.
- function - provided as SUM, the calculation to perform during aggregation.
Note that the Year totals are the same as in the previous example; only the arrangement of the data is different.
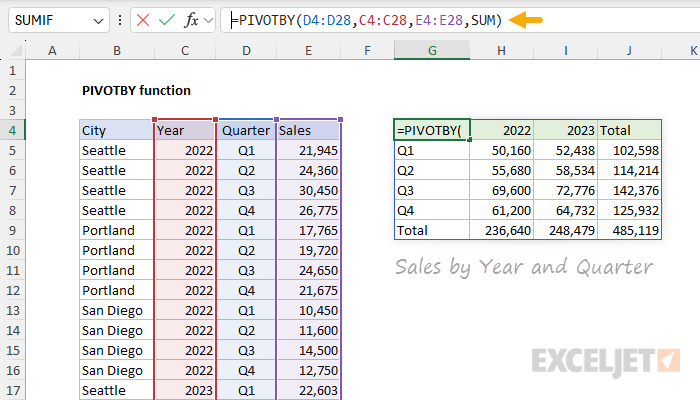
PIVOTBY rows vs. columns
Compared to the GROUPBY function (which groups only by row) the main benefit of PIVOTBY is the ability to group by row and by column. This behavior is governed by the first two arguments, row_fields and col_fields. To illustrate how this works, let's look at what happens when we swap row fields with column fields. In the first table, we use PIVOTBY to group rows by City and columns by Year:
=PIVOTBY(B4:B28,C4:C28,E4:E28,SUM)
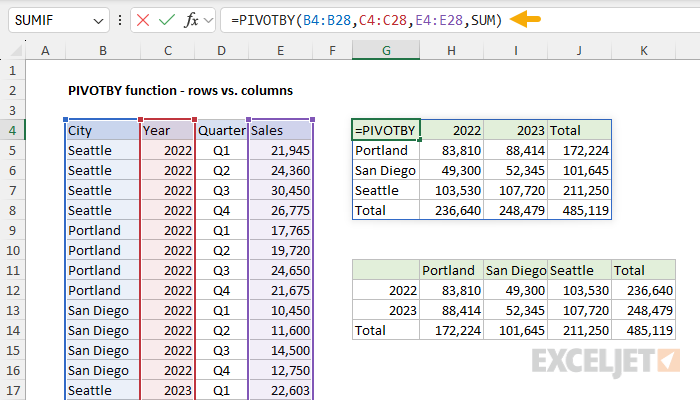
In the second table, we swap rows and columns. Now we group rows by Year and columns by City:
=PIVOTBY(C4:C28,B4:B28,E4:E28,SUM)
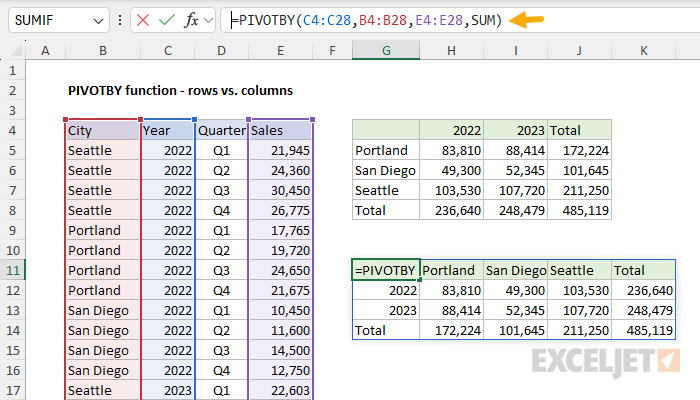
Again, note that all totals are the same. The only difference is the orientation of the table.
PIVOTBY with field headers
The fifth argument in PIVOTBY, field_headers, controls how the header row is handled when it is part of the data provided to the PIVOTBY function. The are five possible values for field_headers:
| Value | Meaning |
|---|---|
| Automatic header detection (default). | |
| 0 | Headers are not provided in the data. |
| 1 | Headers are included, but should not be displayed. |
| 2 | Headers are not included but should be generated. |
| 3 | Headers are included and should be displayed. |
The field_header argument is optional. When field_header is omitted, PIVOTBY will try to detect headers in the source data automatically by testing values. If the first value is text and the second value is numeric, PIVOTBY will assume the first row contains headers. However, automatic detection only prevents the headers from being processed as values; it does not display headers. To display field headers in source data, you must specifically enable them by setting field_header to 3. You can see how this works in the example below, where the ranges provided for row_fields and values include a header row, and field_header is provided as 3:
PIVOTBY(B4:B28,,E4:E28,SUM,3) // display field headers
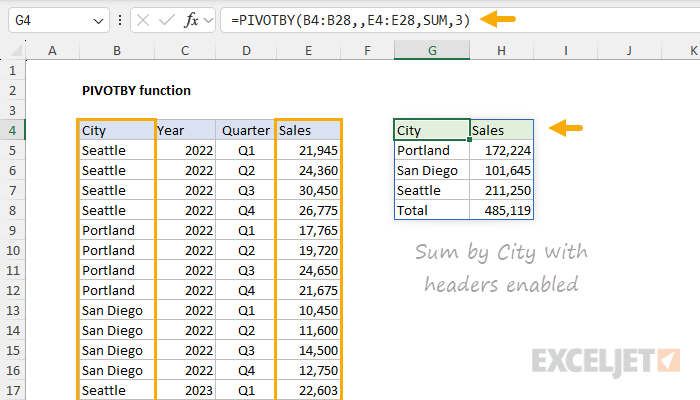
The inputs to PIVOTBY are as follows:
- row_fields - provided as the range B4:B28, which contains city names.
- col_fields - omitted, no value provided.
- values - provided as the range E4:E28, which contains sales amounts.
- function - provided as SUM, the calculation to perform during aggregation.
- field_headers - provided as 3, to display field headers.
Notice we have not provided any value for col_fields to keep the table generated by PIVOTBY simple. When col_fields are included, and field headers are set to display, the resulting table can become more complicated. This example also illustrates that while row_fields and col_fields are marked as required fields, both values are not required in the same formula. In other words, you must provide either row_fields or col_fields, but you aren't required to provide both.
PIVOTBY calculation options
The fourth argument in PIVOTBY is called "function". The function argument specifies which calculation to run when values are grouped. You can use Excel functions like SUM, AVERAGE, COUNT, COUNTA, MAX, MIN, etc. As you enter a PIVOTBY formula, Excel will display a list of suggested functions when you get to the function argument, as seen below:
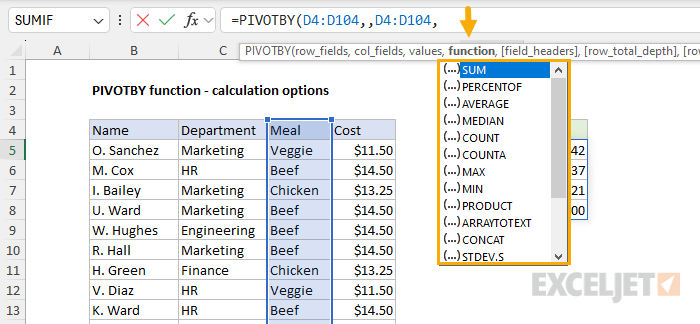
In the worksheet below, we have a list of meal preferences for 100 employees in different departments and the cost per meal. We can use the PIVOTBY function to generate a count for each meal (Beef, Chicken, and Veggie) by using COUNTA for function. In the worksheet below, the formula in G5 looks like this:
=PIVOTBY(D4:D104,,D4:D104,COUNTA,1)
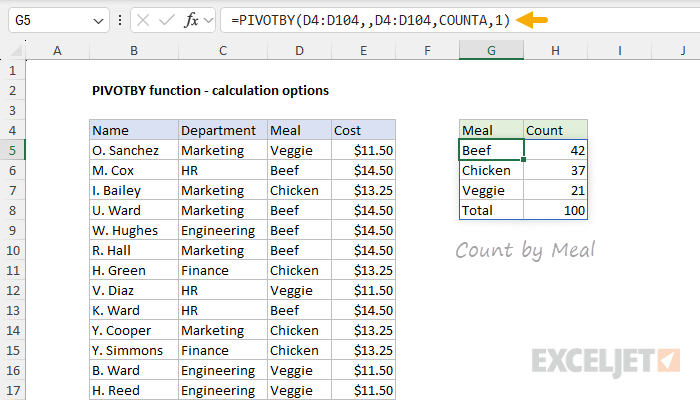
- row_fields - D4:D104 (Meal), because we want to group by meal.
- col_fields - not provided.
- values - D4:D104 (Meal) because we want to count meals.
- function - COUNTA, because we want to count text values.
- field_headers - 1 (don't show), because we have our own headers in G4:H4.
Notice that COUNTA is called with eta lambda syntax: just the function name, without parentheses and arguments. We use COUNTA instead of COUNT in this case because we are counting text values. Also note that although field headers are included in the source data ranges, we provide 1 for field_headers to suppress them. We do this because the "default" headers created by PIVOTBY in this case are not helpful. The solution is to hardcode our own headers in G4:H4.
Next, let's change the calculation to generate a total cost by meal, by using the SUM function instead of COUNTA. In the worksheet below, the formula in G5 now looks like this:
=PIVOTBY(D4:D104,,E4:E104,SUM,1)
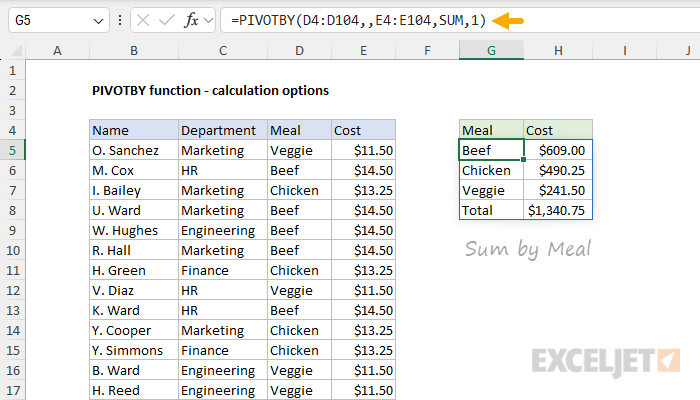
- row_fields - D4:D104 (Meal), because we want to group by meal.
- col_fields - not provided.
- values - E4:E104 (Cost) because we want to sum Cost.
- function - SUM, because we want a total per Meal.
- field_headers - 1, (don't show), because we have our own headers in G4:H4.
Note: PIVOTBY does not provide automatic formatting, so we have manually applied the Currency number format to H5:H8.
In the worksheet below, we have modified the original formula above to provide a count by meal and by department. The formula in G4 is:
=PIVOTBY(C4:C104,D4:D104,D4:D104,COUNTA,1)
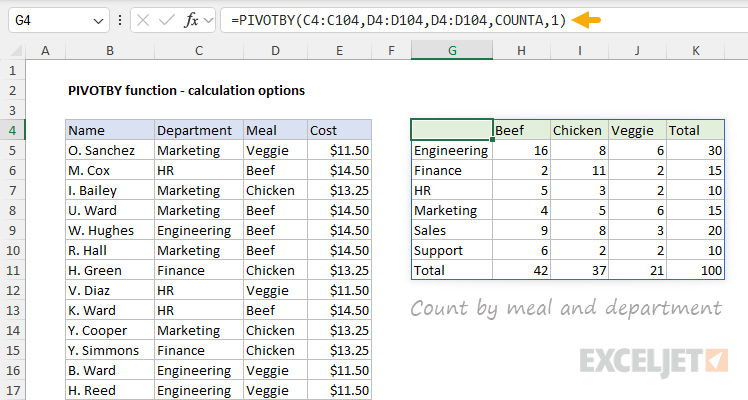
- row_fields - C4:C104 (Meal), to group rows by Department.
- col_fields - D4:D104 (Meal), to group columns by Meal.
- values - D4:D104 (Meal), to count Meal values.
- function - COUNTA, to count text values.
- field_headers - 1, (don't show), because the generated headers are not useful.
Note: the values in G4:K4 are not field headers. They are Meal values grouped by column.
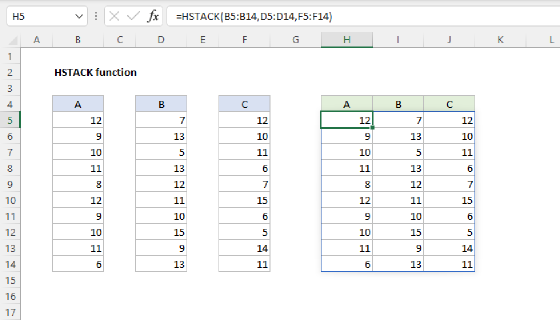
PIVOTBY with multiple calculations
PIVOTBY can generate more than one calculation in the same table, but it is not obvious how to do so, since the function argument accepts just one value. The trick is to use the HSTACK function inside PIVOTBY to call more than one function simultaneously. For example, in the worksheet below, we are using PIVOTBY to count by meal and sum by meal at the same time. The formula in G4 looks like this:
=PIVOTBY(D4:D104,,E4:E104,HSTACK(COUNT,SUM),1)
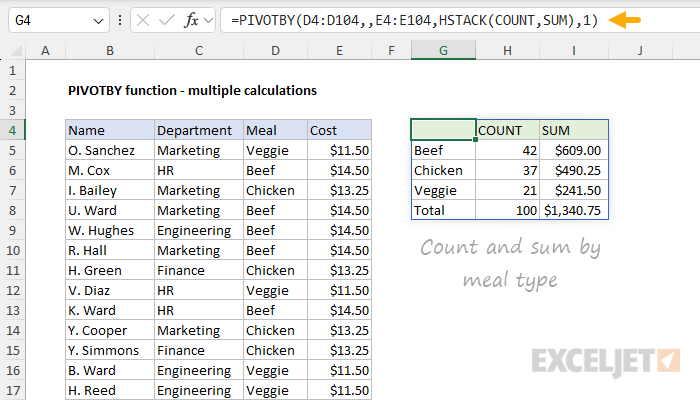
- row_fields - D4:D104 (Meal), because we want to group by meal.
- col_fields - not provided.
- values - E4:E104 (Cost) because we want to sum the cost.
- function - HSTACK(COUNT,SUM), because we want to count and sum
- field_headers - 1, because the data contains a header row we don't want to display.
Notice that the formula is now entered in cell G4, even though we have set field_headers to 1 (do not display). PIVOTBY automatically generates "calculation headers" when you ask for multiple calculations. As a result, we have "COUNT" in H4 and "SUM" in I4. Moving the formula to cell G4 keeps the table in the same place and essentially uses the calculation labels as headers.
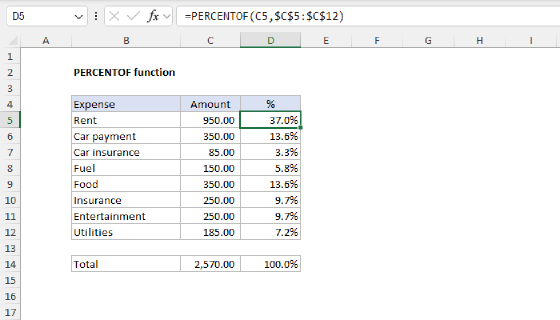
To perform another calculation, we can add it to the values inside HSTACK. In the example below, we have added the PERCENTOF function to HSTACK, and the formula in G4 is now:
=PIVOTBY(D4:D104,,E4:E104,HSTACK(COUNT,SUM,PERCENTOF),1)
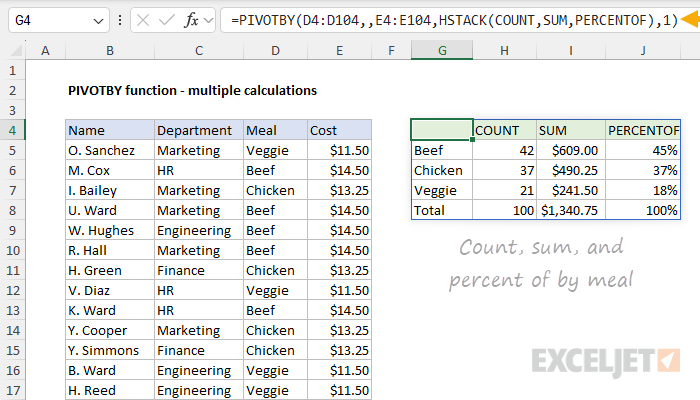
Note that the formatting in the table seen above has been applied manually. Also, notice that the structure of the headers in the table is not ideal. The first column lacks a header, and the function names used for calculations are a bit clunky since they just the raw uppercase function names. We'll tackle this problem in the next section.
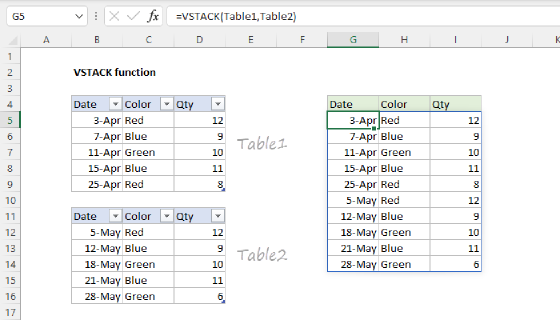
PIVOTBY with custom headers
When you add multiple calculations to the PIVOTBY function, it automatically generates headers for the calculated columns. Depending on your use case, you may want to discard these headers and use your own. To do that, you can "drop" the header row with the DROP function and then join your custom headers to the remaining table data with the VSTACK function. You can see an example of this in the example below, which performs three calculations: COUNT, SUM, PERCENTOF. The formula in cell G4 looks like this:
=VSTACK(
{"Meal","Count","Cost","%"},
DROP(PIVOTBY(D4:D104,,E4:E104,HSTACK(COUNT,SUM,PERCENTOF),1),1)
)
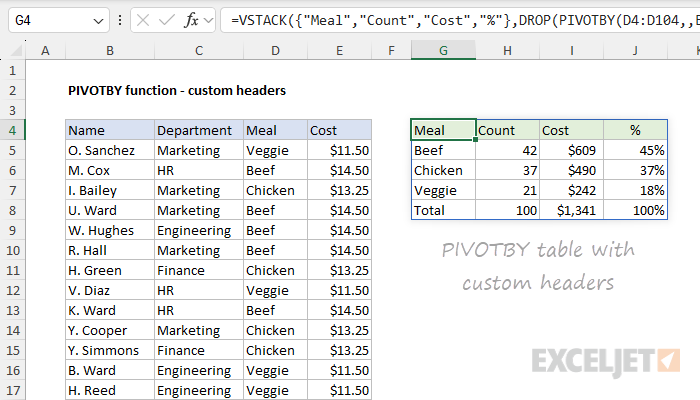
- Inside the DROP function, we have the original PIVOTBY formula.
- DROP removes the header row and passes the result into VSTACK.
- VSTACK stacks the custom headers on top of the remaining table.
Note that the headers in G4:J4 come from custom values supplied as an array constant like {"Meal","Count","Cost","%"}. You are free to customize these values as you like. As an alternative "hybrid" solution, you can enter the header values manually in row 4 and then use a DROP + PIVOTBY formula in cell G5 to output just the table data returned by PIVOTBY:
=DROP(PIVOTBY(D4:D104,,E4:E104,HSTACK(COUNT,SUM,PERCENTOF),1),1)
With either approach above, you have full control over the headers above the PIVOTBY-generated table. However, if you change the table layout, you will need to resync the custom headers manually to the new table.
PIVOTBY with multiple columns
The PIVOTBY function can handle multiple columns for row_fields, col_fields, and values arguments. When you include multiple columns, the output will have multiple row group levels. To illustrate how this works, consider the examples below. In the first example, we provide one column for row_fields, and 1 column for values. The formula in G4 looks like this:
=PIVOTBY(C4:C226,,E4:E226,SUM,3)
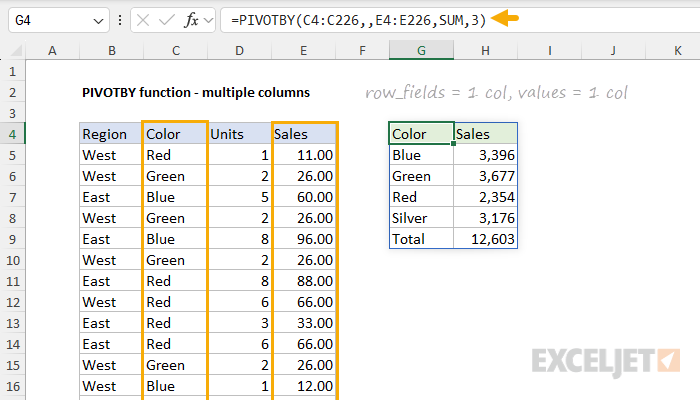
PIVOTBY is configured as follows:
- row_fields - Color (C4:C226), including the header row.
- col_fields - not provided.
- values - Sales (E4:E226), including the header row.
- function - SUM to generate a total for each color.
- field_headers - 3, since the source data includes a header row that should be displayed.
With this configuration, PIVOTBY groups Sales by Color and generates a total for Red, Green, Blue, and Silver as shown above. Now let's look at what happens when we add another column (Region) to row_fields. In the example below, we've modified the formula to include Region and Color for row_fields:
=PIVOTBY(B4:C226,,E4:E226,SUM,3)
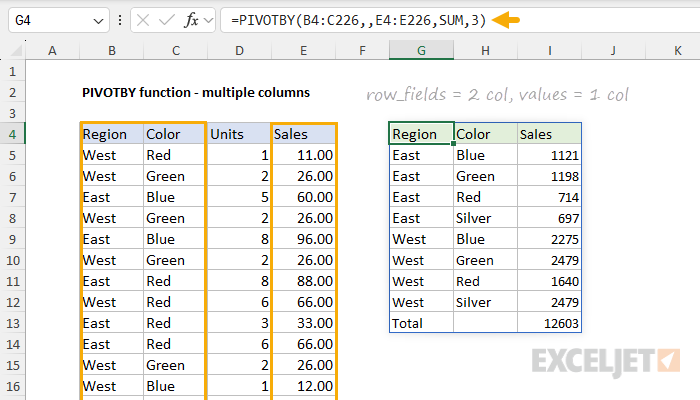
- row_fields - Region and Color (B4:C226), including the header row.
- col_fields - not provided.
- values - Sales (E4:E226), including the header row.
- function - SUM to generate a total for each region/color.
- field_headers - 3, since the source data includes a header row that should be displayed.
The result is that PIVOTBY groups Sales by Region and Color, and returns total Sales for each combination. In the same way, values can also be expanded to a range with two columns, and PIVOTBY will add a new calculated column. In the example below, we have expanded the range provided for values to include Units. The formula in G4 is:
=PIVOTBY(B4:C226,,D4:E226,SUM,3)
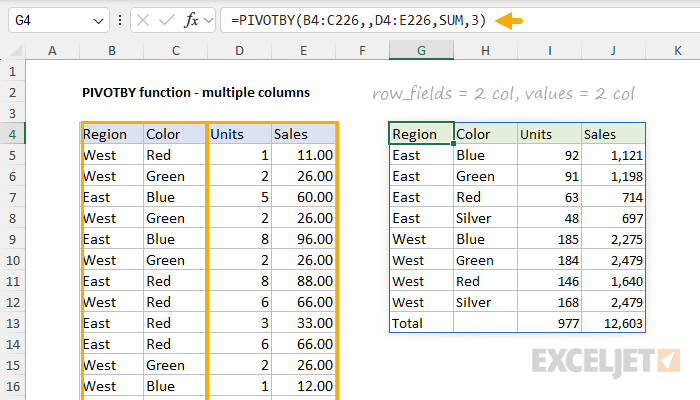
- row_fields - Region and Color (B4:C226), including the header row.
- col_fields - not provided.
- values - Units and Sales (D4:E226), including the header row.
- function - SUM to generate totals for each region/color.
- field_headers - 3, since the source data includes a header row that should be displayed.
Notice that the PIVOTBY function now generates two totals for each Region/Color combination: a total for Units and a total for Sales.
You can also supply multiple columns for col_fields. However, it is generally harder to control the layout in this case because the table tends to expand horizontally very quickly and you end up with extra "header" labels at the top that are difficult to decipher.
PIVOTBY total options
PIVOTBY has two optional arguments to control how grand totals and subtotals are displayed in the final output: row_total_depth and col_total_depth. When these arguments are not provided, PIVOTBY will automatically display grand totals. The table below shows the values that can be provided for both arguments:
| Value | Meaning |
|---|---|
| Automatic grand totals (default). | |
| 0 | Do not display totals. |
| 1 | Display Grand Totals. |
| 2 | Display Grand Totals and Subtotals. |
| -1 | Display Grand Totals at top. |
| -2 | Display Grand Totals and Subtotals at top. |
The word "depth" refers to the hierarchy created when you supply more than one column of data for row_fields or col_fields. If you only have a single column of data for row_fields or col_fields, you only have a depth of 1. This means you can display grand totals but not subtotals. Only by adding more columns to you increase depth and therefore make it possible to display subtotals.
In most cases, you will be working with row totals, since most reports have a vertical orientation. As mentioned above, PIVOTBY will create and display grand totals when row_total_depth argument is not provided. You can see how this works below, where the formula in cell G4 looks like this:
=PIVOTBY(B4:C226,,E4:E226,SUM,3)
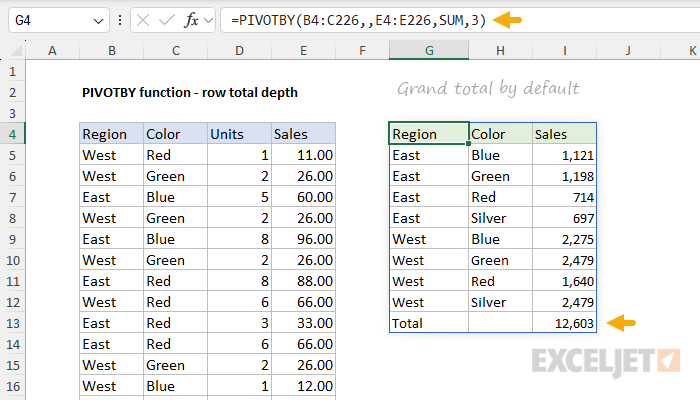
- row_fields - Region and Color (B4:C226), including the header row.
- col_fields - Not provided.
- values - Sales (E4:E226), including the header row.
- function - SUM to generate totals for Sales
- field_headers - 3, to display a header row.
- row_total_depth - not provided.
Note that the total in cell I13 is displayed by default. If we explicitly enable grand totals by setting total_depth to 1, we get the same result:
=GROUPBY(B4:C226,E4:E226,SUM,3,1) // row total depth = 1
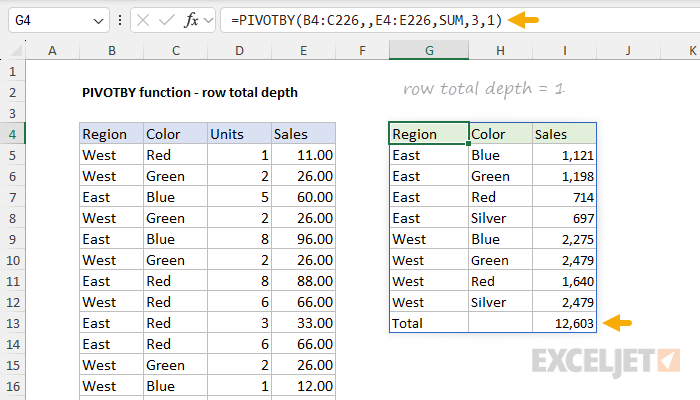
- row_fields - Region and Color (B4:C226), including the header row.
- col_fields - Not provided.
- values - Sales (E4:E226), including the header row.
- function - SUM to generate totals for Sales
- field_headers - 3, to display a header row.
- row_total_depth - 1, to explicitly enable a grand total.
Setting row_total_depth to 2 enables both grand totals and subtotals, as shown in the example below:
=PIVOTBY(B4:C226,,E4:E226,SUM,3,2) // row total depth = 2
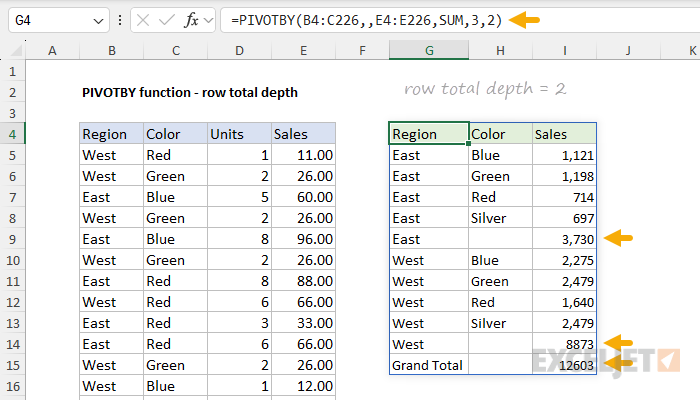
- row_fields - Region and Color (B4:C226), including the header row.
- col_fields - Not provided.
- values - Sales (E4:E226), including the header row.
- function - SUM to generate totals for Sales
- field_headers - 3, to display a header row.
- row_total_depth - 2, to enable subtotals and a grand total.
Now we have subtotals for Region in cells I9 and I14, and a grand total in cell I15.
For subtotals to display, row_fields must have at least 2 columns. If you try to enable subtotals when row_fields contains just one column, PIVOTBY will return a #VALUE! error. It is possible to provide numbers greater than 2 for total_depth as long as row_fields has enough columns to support the requested total depth.
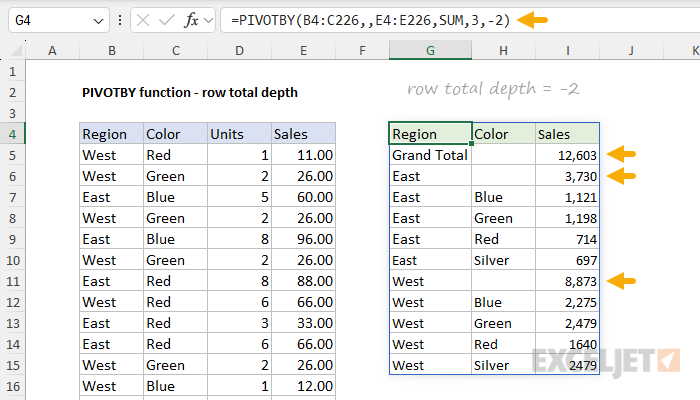
The PIVOTBY function also supports displaying grand totals and subtotals at the top of a group instead of at the bottom. The example below moves grand totals to the top by setting row_total_depth to -1:
=PIVOTBY(B4:C226,,E4:E226,SUM,3,-1) // row total depth = -1
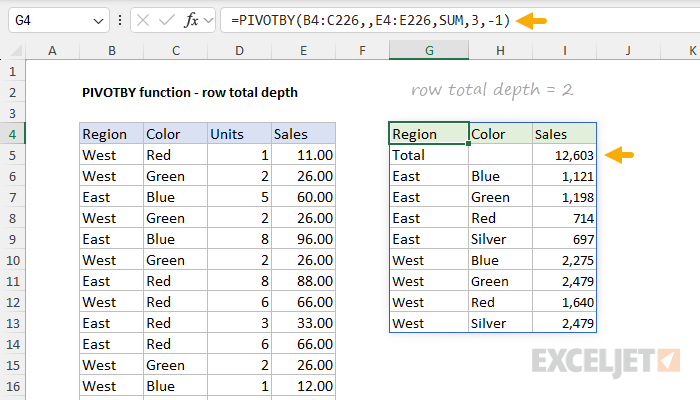
Likewise, subtotals can also be displayed at the top of a group by setting row_total_dept to -2:
=PIVOTBY(B4:C226,,E4:E226,SUM,3,-2) // row total depth = -2
PIVOTBY Sort options
In the same way that PIVOTBY has two arguments to control grand totals and subtotals (row_total_depth and col_total_depth), it also has two arguments to control sorting: row_sort_order and col_sort_order. As the names suggest, row_sort_order controls sorting for row fields, and col_sort_order controls sorting for column fields. Both arguments are optional. When not provided, PIVOTBY will (by default) sort values in standard ascending (A-Z) order — row fields will sort from top to bottom, and column fields will sort from left to right. This behavior is automatic and can't be disabled. You can see an example below, where no sort order has been specified, and the table returned by PIVOTBY is sorted A-Z by city name. The formula in cell G4 looks like this:
=PIVOTBY(B4:B52,,E4:E52,SUM,3) // no sort order provided
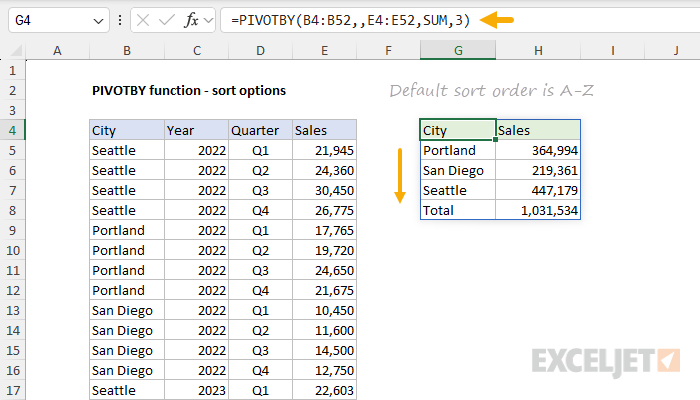
- row_fields - City (B4:B52), including the header row.
- col_fields - not provided.
- values - Sales (E4:E52), including the header row.
- function - SUM to generate totals for Sales
- field_headers - 3, to display a header row.
- row_total_depth - not provided.
- row_sort_order - not provided.
To override the default row sort order, provide a value for the row_sort_order argument, which is given as an index number that can be positive (A-Z) or negative (Z-A). The number itself corresponds to the columns in the table, starting with 1 for the first column. For example, to sort the table by city name in descending (Z-A) order, use a -1:
=PIVOTBY(B4:B52,,E4:E52,SUM,3,,-1) // sort by city Z-A
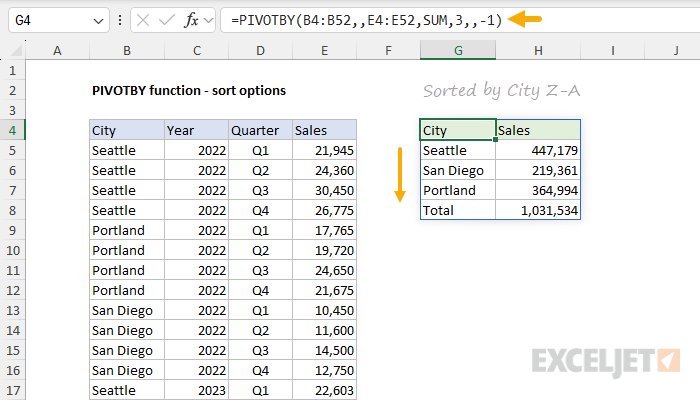
- row_fields - City (B4:B52).
- col_fields - not provided.
- values - Sales (E4:E52).
- function - SUM to generate totals for Sales
- field_headers - 3, to display a header row.
- row_total_depth - not provided.
- row_sort_order - provided as -1 to sort by City Z-A.
To sort the table by Sales in ascending order, provide a 2 row_sort_order, where 2 means the second column:
=GROUPBY(B4:B16,D4:D16,SUM,3,,2)
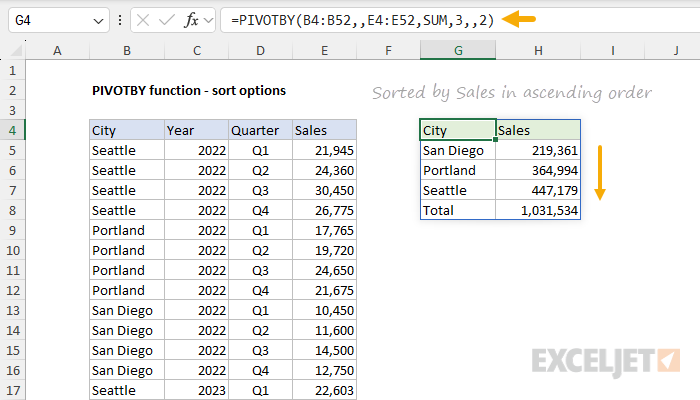
To sort the table by Sales in descending order, provide a -2 for row_sort_order, where the 2 means the second column and the negative sign (-) means a descending (Z-A) sort:
=PIVOTBY(B4:B52,,E4:E52,SUM,3,,-2)
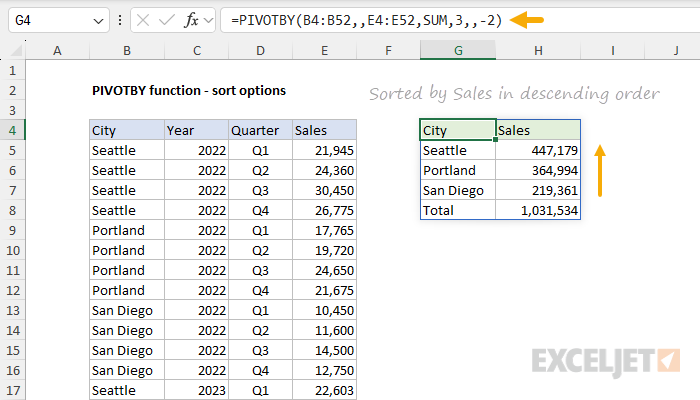
Rows and columns can be sorted at the same time. In the worksheet below, we've sorted rows by sales in descending order and
sorted columns by year in descending order:
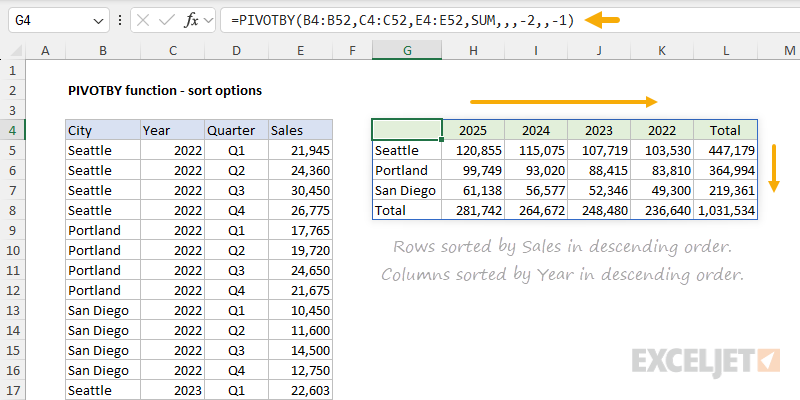
- row_fields - City (B4:B52).
- col_fields - Year (C4:C52).
- values - Sales (E4:E52).
- function - SUM to generate totals for Sales
- row_sort_order - provided as -2 to sort by Sales in descending order.
- row_sort_order - provided as -1 to sort by Year in descending order.
PIVOTBY with a filter array
The PIVOTBY function can filter incoming data to exclude specific values. This feature is controlled by the optional filter_array argument, which essentially acts as a "filter" to remove specific rows of data. When provided, filter_array should be an array of Boolean values (i.e., TRUE and FALSE, or 1s and 0s) that match the size of the data. In other words, if the data contains 100 rows of data, the filter_array should contain 100 Boolean values. Only rows associated with TRUE (or 1) will make it past the filter into the final output. The Booleans in the filter_array are typically generated with a logical expression. For example, in the workbook below, the data has been filtered to allow only rows where the year is greater than 2023. The logical expression used for filter_array is C4:C52>2023. The result is that the table generated by PIVOTBY only includes 2024 and 2025 (2022 and 2023 are excluded). The formula in G4 looks like this:
=PIVOTBY(B4:B52,C4:C52,E4:E52,SUM,,,,,,C4:C52>2023)
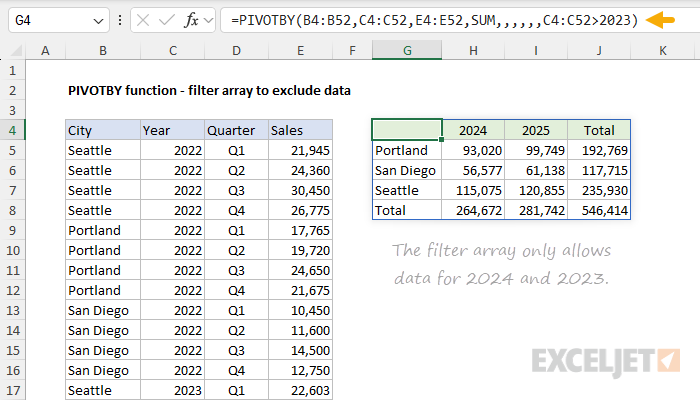
Note that years are easy to work with in this example because they are numbers. That's why we can use the expression C4:C52>2023 directly to exclude years earlier than 2024. This logic can be easily extended to include more than one condition. In the example below, we extend the existing logical to exclude data for Seattle. The formula in G4 now looks like this:
=PIVOTBY(B4:B52,C4:C52,E4:E52,SUM,,,,,,(C4:C52>2023)*(B4:B52<>"Seattle"))
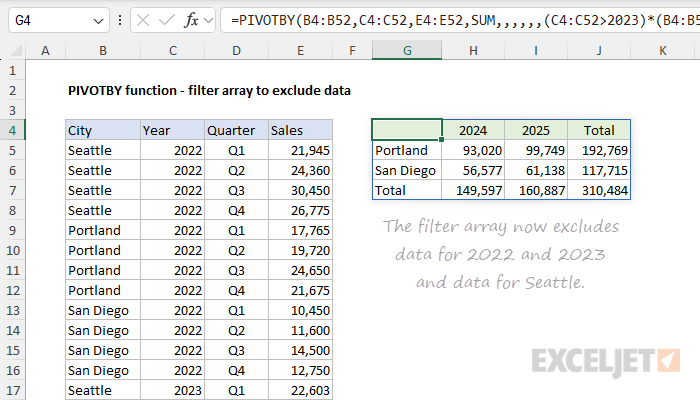
The filter_array is now created by the expression (C4:C52>2023)*(B4:B52<>"Seattle"). This is an example of Boolean logic. For a quick overview, see this 3-minute video: Boolean Algebra in Excel.
See the examples on the FILTER function page for examples of more complex criteria to generate a filter_array. The PIVOTBY function does not need to use FILTER directly (because the filter_array already serves that purpose). However, the logic used inside FILTER's include argument is exactly the same as filter_array, so you can easily port FILTER logic to PIVOTBY. If you need more powerful pattern matching based on Regular Expressions, see the REGEXTEST function.
PIVOTBY with custom LAMBDA
The calculation performed by the PIVOTBY function can be called in two different ways: (1) a short-form "eta lambda syntax" or (2) a long-form syntax that uses a custom LAMBDA function. For example, to group and sum values, the short-form syntax looks like this:
=PIVOTBY(row_fields,col_fields,values,SUM)
The long-form custom syntax for the same calculation looks like this:
=PIVOTBY(row_fields,col_fields,LAMBDA(x,SUM(x))
Both formulas above will return the same result. Why two syntax options? The short form is for convenience. It is concise and easy to read. However, the behavior cannot be customized. The long-form syntax uses the LAMBDA function and can be customized as needed to apply a more advanced calculation. To illustrate this concept, suppose you want the round values that PIVOTBY returns to the nearest 1000. We can use the ROUND function to round to the nearest 1000 like this:
=ROUND(number,-3)
But how do we get this into the PIVOTBY function, which needs to sum the values before rounding them? The trick is to switch to the long-form LAMBDA syntax and use a calculation like this:
LAMBDA(x,ROUND(SUM(x),-3))
The core of this calculation is the long-form syntax LAMBDA(x,SUM(x), plus the ROUND function. The grouped values are passed into SUM, which returns the sum of a given group directly to ROUND, which rounds the number to the nearest 1000. The PIVOTBY function then returns the rounded sum in the final output. You can see an example of this formula in action in the worksheet below, where the formula in cell F4 looks like this:
=PIVOTBY(B4:B28,C4:C28,E4:E28,LAMBDA(x,ROUND(SUM(x),-3)))
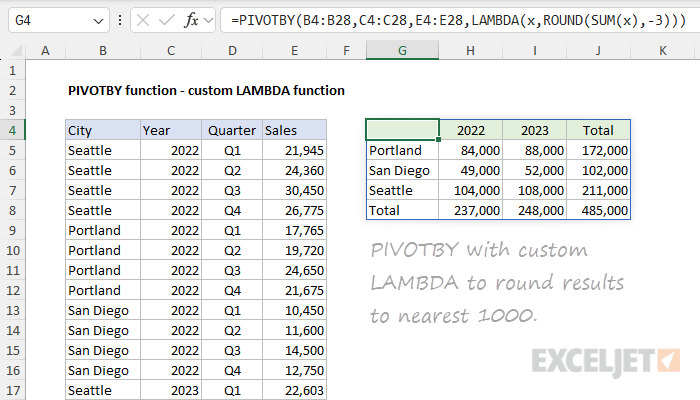
The ROUND example above is just for illustration. Because PIVOTBY supports a custom LAMBDA function, you can run any calculation that makes sense in the context of the PIVOTBY function.
PIVOTBY with a dynamic range
When you use the PIVOTBY function with data that changes frequently, you will probably want to configure it to use a dynamic range. A dynamic range is a range that expands and contracts as rows are added or removed. You have two good options to make the range:
- Convert the data to an Excel Table and provide columns by name.
- Use the TRIMRANGE function to create a dynamic named range.
In both cases, you will then need to feed specific columns of the range into PIVOTBY. With Excel Tables, this is easy, since you can refer to table columns by name. With a named range, you can use the CHOOSECOLS function to access specific columns and, if desired, you could give those columns names by wrapping the formula in the LET function, then feed the names into PIVOTBY.