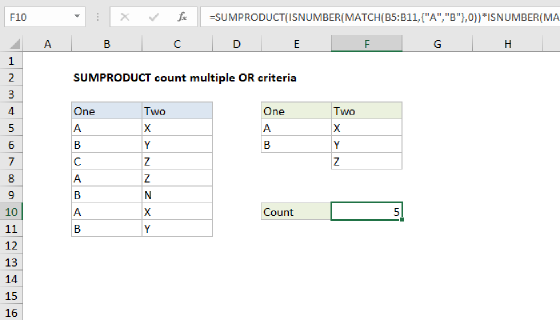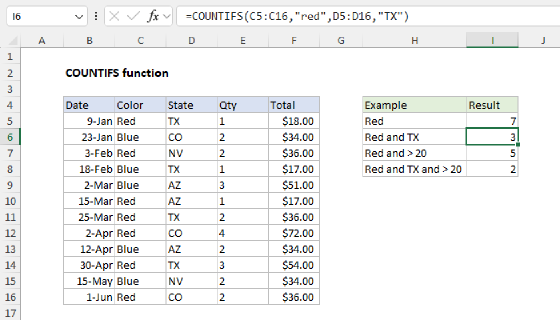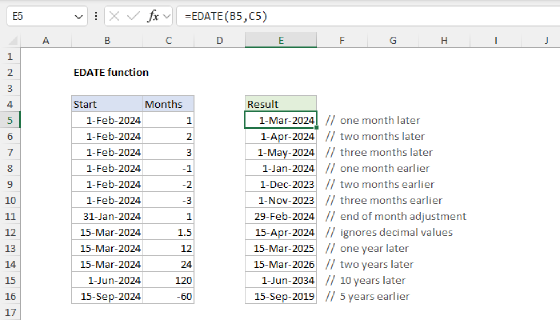
Summary
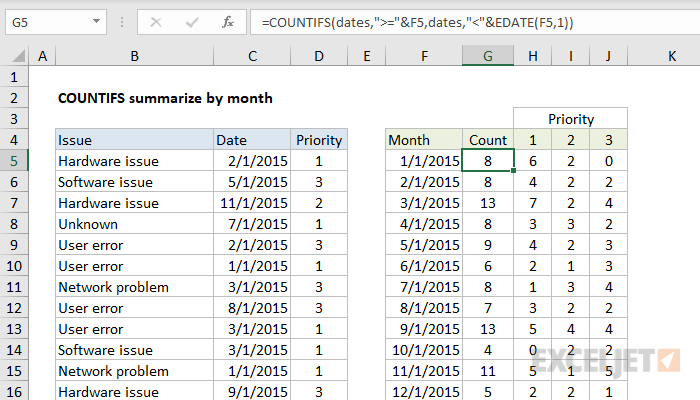
To create a summary count by month, you can use the COUNTIFS function and the EDATE function with two criteria. In the example shown, the formula in G5 is:
=COUNTIFS(dates,">="&F5,dates,"<"&EDATE(F5,1))
Generic formula
=COUNTIFS(dates,">="&A1,dates,"<"&EDATE(A1,1))
Explanation
In this example, we have a list of 100 issues in Columns B to D. Each issue has a date and priority. We are also using the named range dates for C5:C104 and priorities for D5:D105. Starting in column F, we have a summary table that shows a total count per month, followed by a total count per month per priority.
We are using the COUNTIFS function to generate a count. The first column of the summary table (F) is a date for the first of each month in 2015. To generate a total count per month, we need to supply criteria that will isolate all the issues that appear in each month.
Since we have actual dates in column F, we can construct the criteria we need using the date itself, and a second date created with the EDATE function. These two criteria appear inside COUNTIFS like so:
dates,">="&F5,dates,"<"&EDATE(F5,1)
Roughly translated: "dates greater than or equal to the date in F5 and less than the date in F5 plus one month". This is a convenient way to generate "brackets" for each month based on a single date.
When the formula is copied down column G, COUNTIFS generates the correct count for each month.
Note: if you don't want to see full dates in column F, just apply the custom date formats "mmm" or "mmmm" to display the month names only.
With Priority
To generate a count by priority, we need to extend criteria. The formula in H5 is:
=COUNTIFS(dates,">="&$F5,dates,"<"&EDATE($F5,1),priorities,H$4)
Here we've added an additional criteria, the named range priorities paired with H4 for the criteria itself. In this version of the formula, we get a count by month broken down by the priority, which is picked up directly from the header in row 5. This formula uses both mixed references and absolute references to facilitate copying:
- The reference to H4 has the row locked (H$4) so priority doesn't change as the formula is copied down.
- The reference to F5 has the column locked ($F5) so the date doesn't change as the formula is copied across.
- The named ranges dates and priorities are automatically absolute.
Pivot table approach
A pivot table is a good alternative solution to this problem. In general, pivot tables are easier and faster to set up when data is well-structured.