Summary
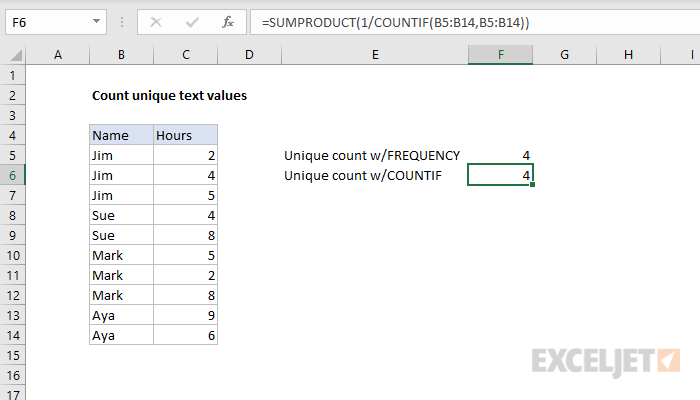
To count the number of unique values in a range of cells, you can use a formula based on the COUNTIF and SUMPRODUCT functions. In the example shown, the formula in F6 is:
=SUMPRODUCT(1/COUNTIF(B5:B14,B5:B14))
In Dynamic Excel, you can use a simpler and faster formula based on UNIQUE.
Generic formula
=SUMPRODUCT(1/COUNTIF(data,data))
Explanation
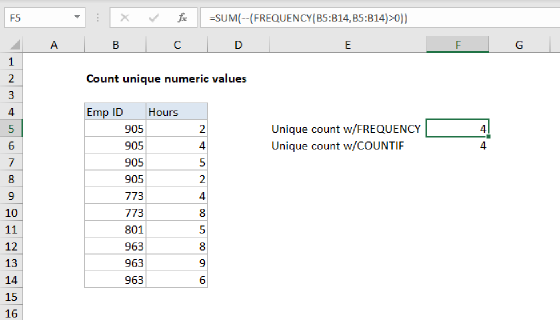
Working from the inside out, COUNTIF is configured to values in the range B5:B14, using all of these same values as criteria:
COUNTIF(B5:B14,B5:B14)
Because we provide 10 values for criteria, we get back an array with 10 results like this:
{3;3;3;2;2;3;3;3;2;2}
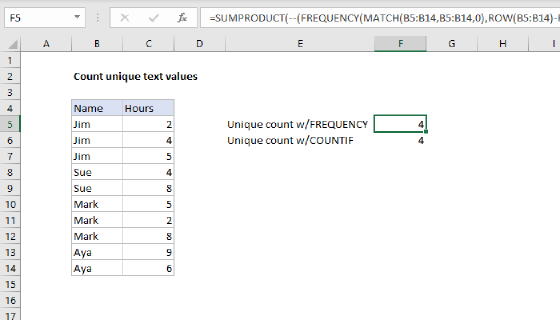
Each number represents a count – "Jim" appears 3 times, "Sue" appears 2 times, and so on.
This array is configured as a divisor with 1 as the numerator. After division, we get another array:
{0.333333333333333;0.333333333333333;0.333333333333333;0.5;0.5;0.333333333333333;0.333333333333333;0.333333333333333;0.5;0.5}
Any values that occur in just once in the range will appear as 1s, but values that occur multiple times will appear as fractional values that correspond to the multiple. (i.e. a value that appears 4 times in data will generate 4 values = 0.25).
Finally, the SUMPRODUCT function sums all values in the array and returns the result.
Handling blank cells
One way to handle blank or empty cells is to adjust the formula as follows:
=SUMPRODUCT(1/COUNTIF(data,data&""))
By concatenating an empty string ("") to the data, we prevent zeros from ending up in the array created by COUNTIF when there are blank cells in the data. This is important, because a zero in the divisor will cause the formula to throw a #DIV/0 error. It works because using an empty string ("") for criteria will count empty cells.
However, although this version of the formula won't throw a #DIV/0 error when with blank cells, it will include blank cells in the count. If you want to exclude blank cells from the count, use:
=SUMPRODUCT((data<>"")/COUNTIF(data,data&""))
This has the effect of canceling out the count of blank cells by making the numerator zero for associated counts.
Slow Performance?
This is a cool and elegant formula, but it calculates much more slowly than formulas that use FREQUENCY to count unique values. For larger data sets, you may want to switch to a formula based on the FREQUENCY function. Here's a formula for numeric values, and one for text values.
UNIQUE function in Excel 365
In Excel 365, the UNIQUE function provides a better, more elegant way to list unique values and count unique values.