Summary
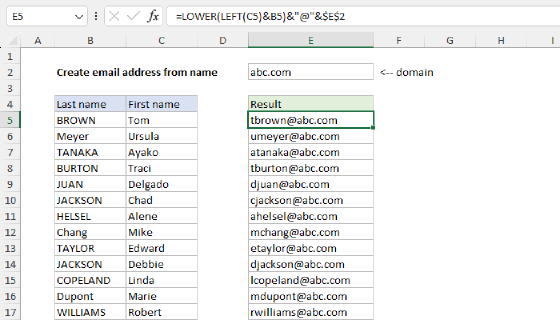
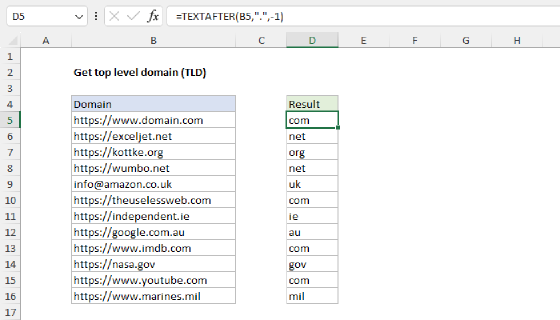
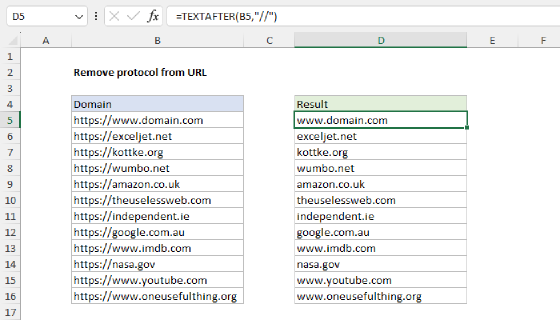
To extract the domain from a URL path you can use a formula based on the TEXTAFTER and TEXTBEFORE functions. In the worksheet shown, the formula in cell C5 is:
=TEXTBEFORE(TEXTAFTER(B5,"//"),"/")
As the formula is copied down, it returns the domain name from each of the URLs shown in column B.
Note: TEXTAFTER and TEXTBEFORE are new functions in Excel. In older versions of Excel, you can use a more complicated formula based on the LEFT and FIND functions, as explained below.
Generic formula
=TEXTBEFORE(TEXTAFTER(url,"//"),"/")
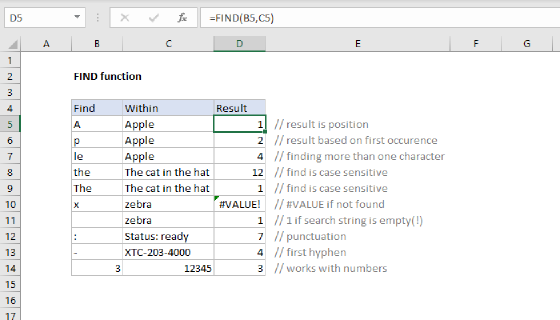
Explanation
In this example, the goal is to extract the domain name from a list of URLs. In the current version of Excel, the easiest way to do this is to use a formula based on the TEXTAFTER and TEXTBEFORE functions. In older versions of Excel, you can use a more complicated formula based on the LEFT and FIND functions. Both approaches are explained below.
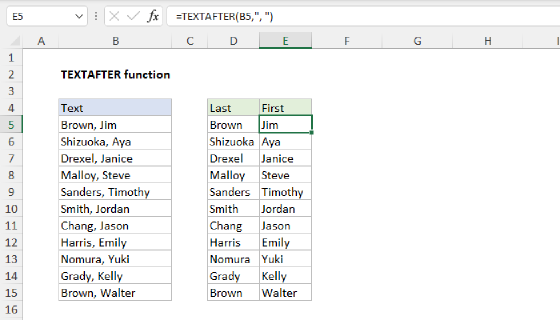
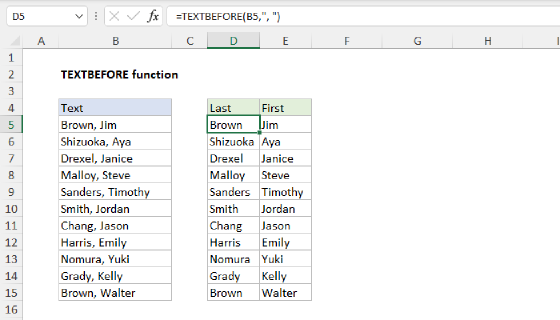
TEXTAFTER with TEXTBEFORE
The formula in the worksheet shown uses the TEXTAFTER and TEXTBEFORE functions to extract domain names from URLs. As the names imply, the TEXTAFTER function extracts text that occurs after a given delimiter, and the TEXTBEFORE function extracts text that occurs before a given delimiter. To solve this problem, each function needs just two arguments, text and delimiter:
=TEXTAFTER(text,delimiter)
=TEXTBEFORE(text,delimiter)
- text - the text string to split
- delimiter - the place at which to split the text
In the worksheet shown, the formula in cell C5 uses both functions like this:
=TEXTBEFORE(TEXTAFTER(B5,"//"),"/")
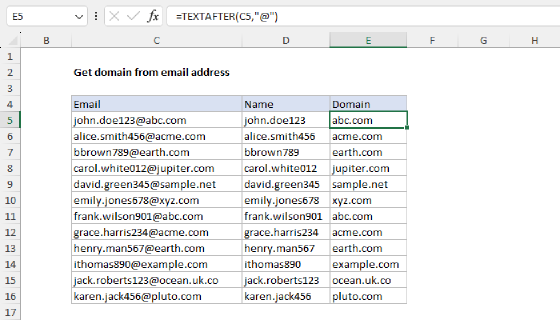
This is an example of nesting one function inside another. Working from the inside out, the TEXTAFTER function is first used to strip the "protocol" from the URL. In this case, the protocol is the text "https://" or "http://". To locate the protocol, we use "//" for the delimiter and provide B5 for text:
TEXTAFTER(B5,"//")
TEXTAFTER locates the double forward slash "//" and returns all text that follows. With the text "https://exceljet.net/formulas/" in cell B5, TEXTAFTER returns "exceljet.net/formulas/". This text is then handed off directly to the TEXTBEFORE function as the text argument for further processing:
=TEXTBEFORE("exceljet.net/formulas/","/")
Here, TEXTBEFORE is configured to use a single forward slash "/" for the delimiter. TEXTBEFORE locates the single forward slash "/" and returns all previous text. The final result is the domain "exceljet.net".
Remove the www
If you want to remove the "www" subdomain from the domain when it is extracted, you can nest the original formula inside the SUBSTITUTE function like this:
=SUBSTITUTE(TEXTBEFORE(TEXTAFTER(url,"//"),"/"),"www.","")
SUBSTITUTE is configured to replace "www." with an empty string (""). If "www." is not found, SUBSTITUTE returns the original result.
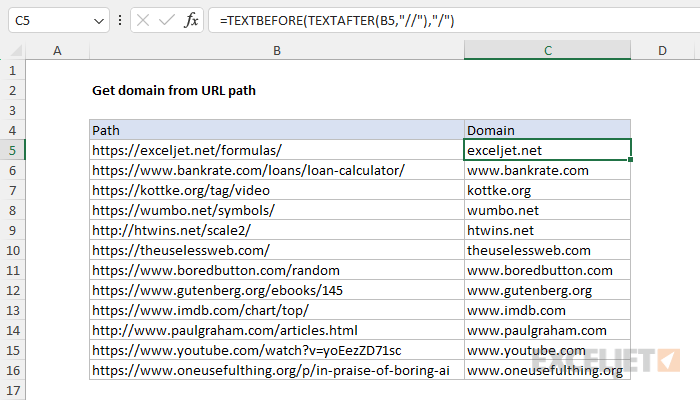
Legacy Excel
In older versions of Excel without the TEXTBEFORE or TEXTAFTER functions, this is a more challenging problem. For a quick solution, you can use a formula like this:
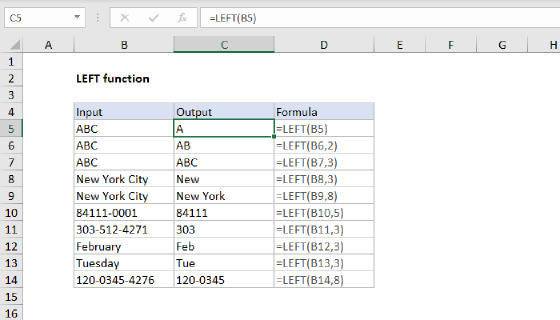
=LEFT(B5,FIND("/",B5,9)-1)
At the core, this formula is extracting characters from the left side of the URL with the LEFT function, and using the FIND function to figure out how many characters to extract. First, FIND locates the "/" character in the URL, starting at the 9th character:
FIND("/",B5,9)
This is the "clever" part of the formula. URLs begin with something called a "protocol" which looks like this:
http://
https://
ftp://
sftp://
By starting at the 9th character, the protocol is skipped, and the FIND function will return the location of the third instance of "/", which is the first instance after the double slash in the protocol. With the text "https://exceljet.net/formulas/" in cell B5, the third instance of "/" is the 21st character in the URL, so FIND returns the number 21. The LEFT function then extracts 21 characters from the URL, starting at the left. The result is the domain name with a trailing slash, "https://exceljet.net/". To get the domain name without a trailing slash, we subtract 1 from the result of FIND like so:
=LEFT(B5,FIND("/",B5,9)-1)
One limitation of this formula is that it leaves the protocol (i.e. "https://") in place. To remove the protocol in a second step, you can use a formula like this:
=MID(C5,FIND("//",C5)+2,LEN(C5))
Essentially, this formula uses the MID function and the FIND function to extract text starting after the "//". The number of characters to extract is provided by the LEN function, which returns the number of characters in cell C5. This is actually a hack to keep things simple. LEN will return 30 in this case, but there are only 20 characters left to extract after the "//". This works because when the number of characters (num_chars) exceeds the remaining string length MID will extract all remaining text. Using LEN to provide num_chars is a simple way to give MID a number that is always large enough.