Summary
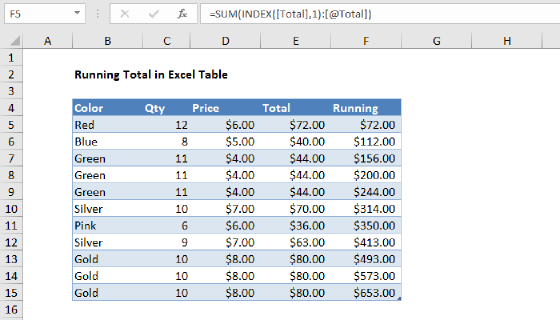
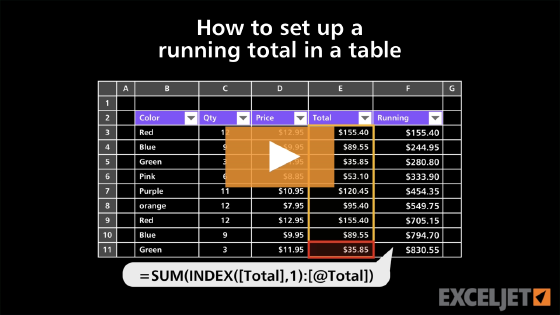
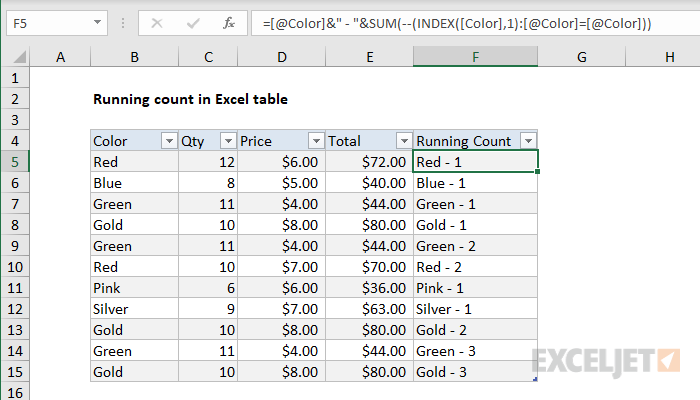
To create a running count in an Excel Table, you can use the INDEX function with a structured reference to create an expanding range. In the example shown, the formula in F5 is:
=[@Color]&" - "&SUM(--(INDEX([Color],1):[@Color]=[@Color]))
When copied down the column, this formula will return a running count for each color in the Color column.
In some versions of Excel, this is an array formula and must be entered with control + shift + enter.
Explanation
At the core, this formula uses INDEX to create an expanding reference like this:
INDEX([Color],1):[@Color] // expanding range
On the left side of the colon (:), the INDEX function returns a reference to the first cell in the column.
INDEX([Color],1) // first cell in color
This works because, the INDEX function returns a reference to the first cell, not the actual value. On the right side of the colon, we get a reference to the current row of the color column like this:
[@Color] // current row of Color
This is the standard structured reference syntax for "this row". Joined with the colon, these two references create a range that expands as the formula is copied down the table. So, we swap these references into the SUM function, we have:
SUM(--(B5:B5=[@Color])) // first row
SUM(--(B5:B11=[@Color])) // last row
Each of the expressions above generates an array of TRUE/FALSE values, and the double negative (--) is used to convert these values to 1s and 0s. So, in the last row, we end up with:
SUM({0;0;0;1;0;0;0;0;1;0;1}) // returns 3
The rest of the formula simply concatenates the color from the current row to the count returned by SUM:
=[@Color]&" - "&3
="Gold"&" - "&3
="Gold - 3"
Simple expanding range?
Why not use a simple expanding range like this?
SUM(--($B$5:B5=[@Color]))
For some reason, this kind of mixed reference becomes corrupted in an Excel Table as rows are added. Using INDEX with a structured reference solves the problem.