Summary
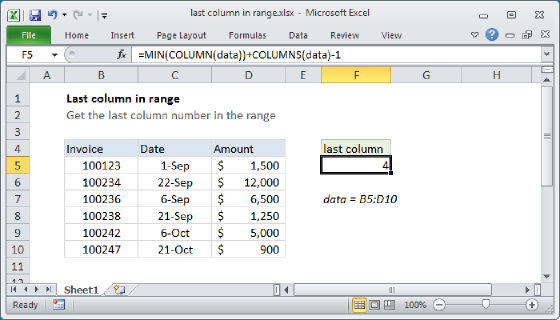
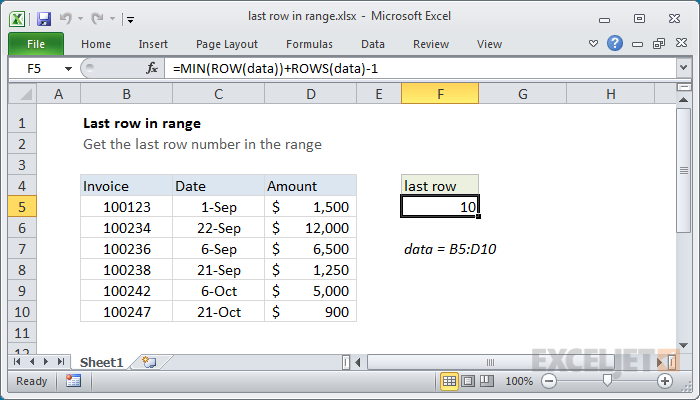
To get the last row number in a range, you can use a formula based on the ROW, ROWS, and MIN functions. In the example shown, the formula in cell F5 is:
=MIN(ROW(data))+ROWS(data)-1
where "data" is the named range B5:D10
Generic formula
=MIN(ROW(rng))+ROWS(rng)-1
Explanation
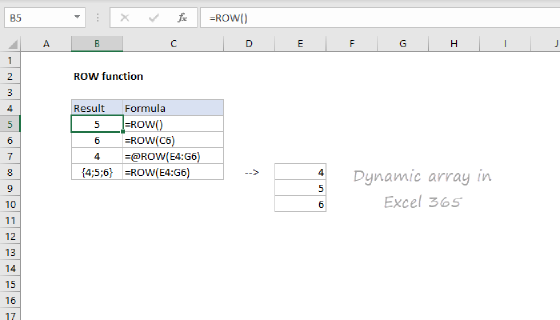
When given a single cell reference, the ROW function returns the row number for that reference. However, when given a range with multiple rows, the ROW function will return an array that contains all row numbers for the range:
{5;6;7;8;9;10}
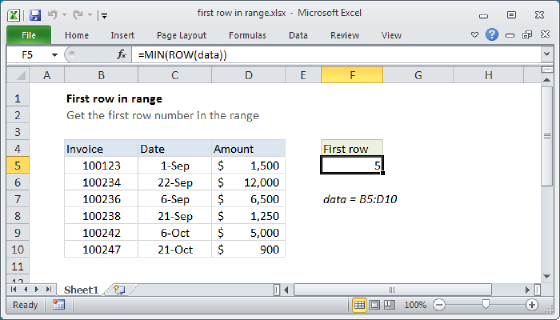
To get the first row number in a range, we use the MIN function like this:
MIN(ROW(data))
which returns the lowest number in the array, 5.
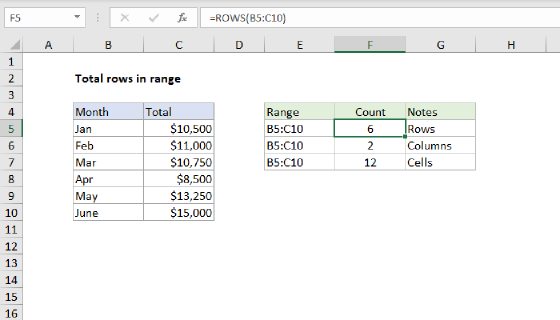
Once we have the first row, we can add the total rows in the range and then subtract 1 to get the last row number. We get total rows in the range with the ROWS function, and a final result is determined like this:
=5+ROWS(data)-1
=5+6-1
=10
Index version
Instead of MIN, you can also use INDEX to get the last row number:
=ROW(INDEX(data,1,1))+ROWS(data)-1
This is possibly a bit faster for large ranges since INDEX returns just a single cell to ROW.
Simple version in older versions of Excel
In Excel 2019 and older, when a formula returns an array result, Excel will display the first item in the array if the formula is entered in a single cell. This means that you will sometimes see a simplified version of the formula like this:
=ROW(data)+ROWS(data)-1
If you only want the last row number in a cell, it works. If you are using this code inside another formula, you may need to ensure you are dealing with only one item and not an array. In that case, you'll want to use the MIN or INDEX version above. In Excel 2021 and later, the formula above will spill a sequence of row numbers starting with the last row number directly on the worksheet.