Summary
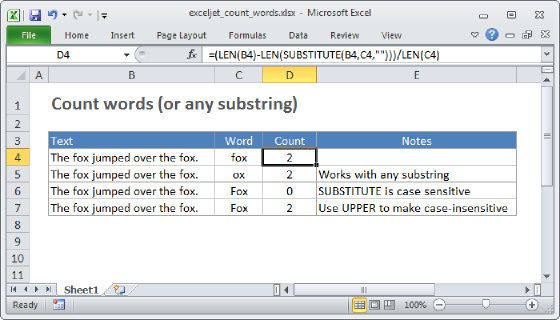
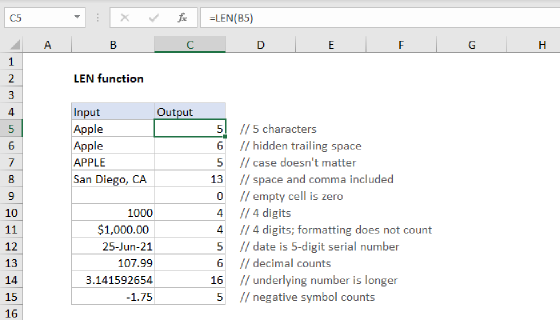
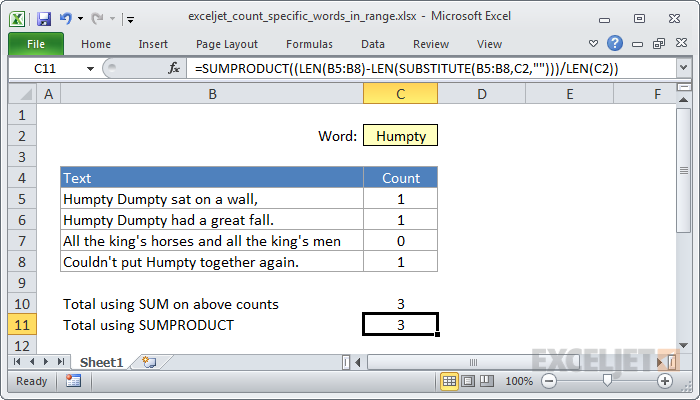
To count how many times a specific a word (or any substring) appears inside a range of cells, you can use a formula based on the SUBSTITUTE, LEN, and SUMPRODUCT functions. In the example shown, the formula in C11 is:
=SUMPRODUCT((LEN(B5:B8)-LEN(SUBSTITUTE(B5:B8,C2,"")))/LEN(C2))
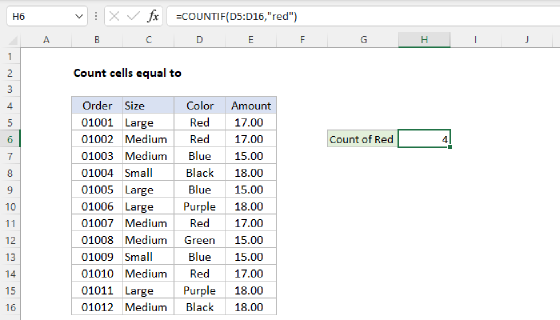
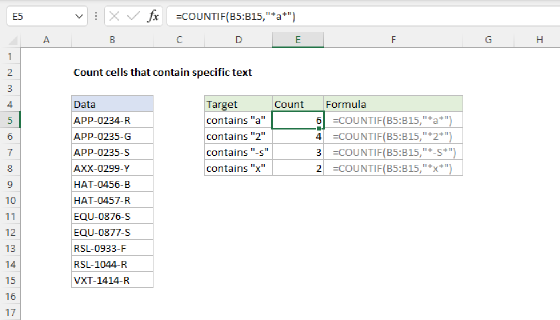
Note: The formula on this page counts instances of a word in a range. For example, if a cell contains two instances of a word, it will contribute 2 to the total count. If you just want to count cells that contain a specific word, see this simple formula based on the COUNTIF function.
Generic formula
=SUMPRODUCT((LEN(rng)-LEN(SUBSTITUTE(rng,txt,"")))/LEN(txt))
Explanation
In the generic version of the formula, rng represents the range to check, and txt is the word or substring to count.
In the example shown, B5:B8 is the range to check, and C2 contains the text (word or substring) to count.
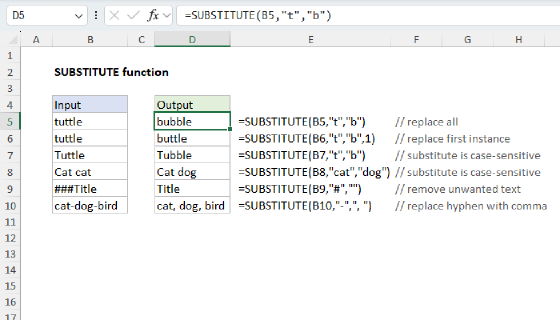
For each cell in the range, SUBSTITUTE removes the substring from the original text and LEN calculates the length of the text without the substring. This number is then subtracted from the length of the original text. The result is the number of characters that were removed by SUBSTITUTE.
Then, the number of characters removed is divided by the length of the substring. So, if a substring or word is 5 characters long, and there are 10 characters missing after it's been removed from the original text, we know the substring/word appeared twice in the original text.
Because the above calculation is wrapped in the SUMPRODUCT function, the result is an array that contains a number for each cell in the range. These numbers represent the number of occurrences of the substring in each cell. For this example, the array looks like this: {1;1;0;1}
Finally, SUMPRODUCT sums together all items in the array to get the total occurrences of substring in the range of cells.
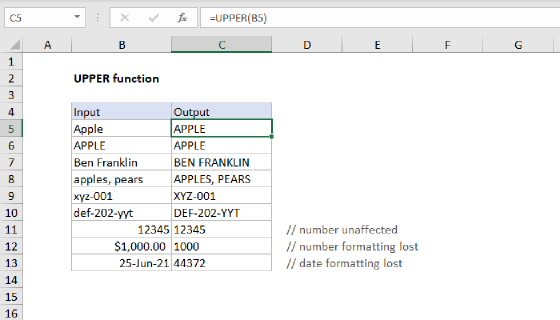
Ignoring case
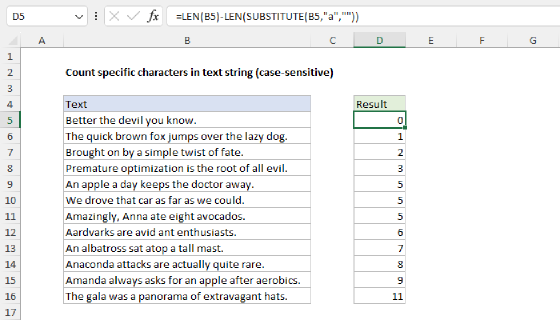
SUBSTITUTE is a case-sensitive function, so it will match case when running a substitution. If you need to count both upper and lower case occurrences of a word or substring, use the UPPER function inside SUBSTITUTE to convert the text to uppercase before running the substitution:
=SUMPRODUCT((LEN(rng)-LEN(SUBSTITUTE((UPPER(rng)),UPPER(txt),"")))/LEN(txt))